

11 Useful BigQuery Tricks (for Newbies)
Tricks Every New BigQuery User Should Know


My ability to write SQL has unlocked many doors for me. It’s allowed me to interact with some amazing tools and database systems. It’s led me to some smart people, interesting companies, and enabled me to solve problems for countless people.
It’s taught me a lot about logic and analytical thinking, not just with data but in life too — if you would believe that.
I’ve seen SQL used to build some pretty cool things. I’ve seen good SQL, bad SQL, and everything in between (no pun intended). SQL is the cornerstone of any solid data organization.
Long story short, it’s a must-have skill if you’re going to make it as a data person.
Over the years, I’ve seen my share of systems that use SQL: SQL Server, MySQL, PostgreSQL, MariaDB, Oracle, Amazon Aurora, SQLite, Snowflake, Databricks, and BigQuery. That’s off the top of my head. Some are darn good; others, well… aren’t.
The one I like playing with the most is BigQuery. It’s fun, and if you’re new at this SQL thing, a great place to stretch your wings. If you’re an old hand at this, then it will be fun and challenging too — I promise.
For me, I get a kick out of using it. Its solid integration with other GCP thingamabobs and thingamajigs adds an interesting twist to working with SQL.
SQL is a Big Hammer
I see SQL as a sledgehammer, and BigQuery is a pretty BIG hammer, but it can also be a pretty neat tool too (in the right hands). It chugs and slugs its way through data whether you know what you’re doing or not.
Now, SQL isn’t as sexy as, say, Python or JavaScript, but if you know SQL and you know what you’re doing, then you have the power. If you work in data or plan to, well, you’re laying some solid foundations.
Side notes:
When I say “know SQL,” I don’t mean you know how to ask ChatGPT what to do. I mean you know how to write good SQL (clean, efficient, and production-grade). You know how the SQL engine thinks.
SQL isn’t going anywhere either. Please don’t believe anyone who says otherwise. If anyone tells you this, you can and should laugh them out of the room with a thumbs up.
I digress…
I’ve been using BigQuery for a good chunk of time now. Long enough to know a few things, so I figured I’d drop some of the things newbies ought to know.
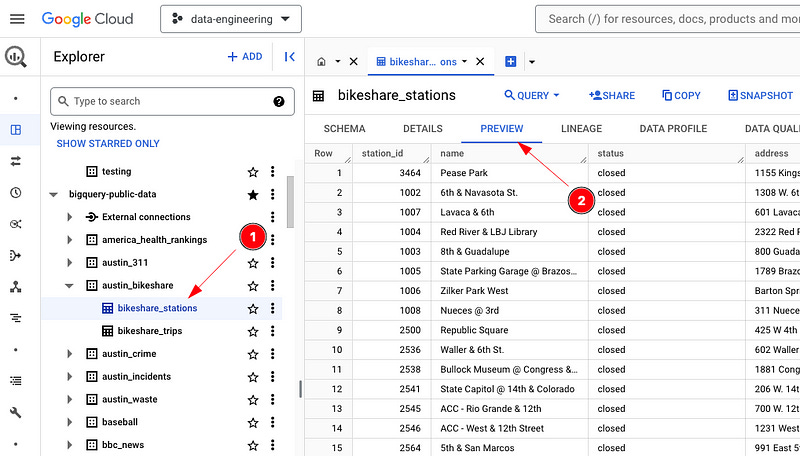
1 — The Preview Button
Simple, I know, but the preview button saves tons of time. It gives you an instant bird’s-eye view of a table before you start diving into it.
Where to find it:
Go to the table in BigQuery Explorer.
Click the table you are after.
Then hit the big PREVIEW tab (You cannot miss it).
Boom, a quick view of the table, columns, what the data looks like, and a great place to start when you’re not familiar with the table you’re dealing with.”om a quick view of the table, columns, what the data looks like ,and a great place to start when you’re not familiar with the table you’re deailing with.
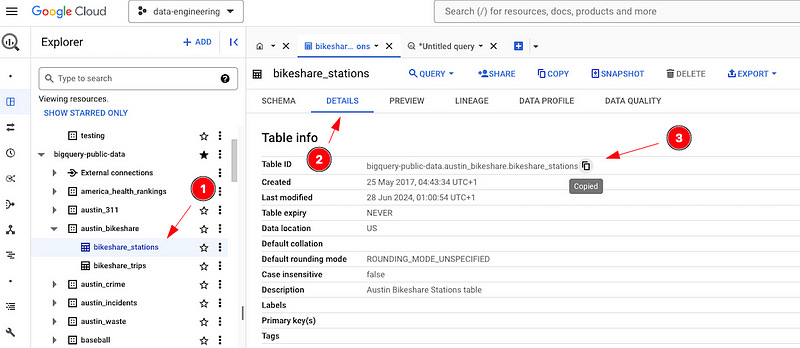
2 — Grab the Table Name (for Lazy Folks, like me)
Sometimes I need to grab the table ID — the full table ID including project ID and dataset ID. One, because I’m too lazy to type it, or two, I’ve tried typing but it’s just not my day.
Where to find it:
Go to the table in BigQuery Explorer.
Hit the Details tab.
Then copy the table ID. Job done.
This is super useful and easy too. I probably do this at some stage during the day.
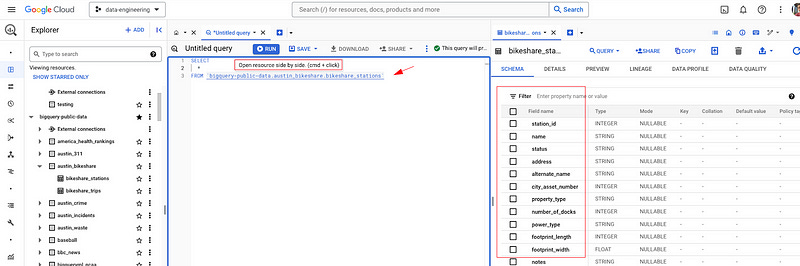
3 — Side by Side Schema Check
Love this feature. If you’re working on a table, you hit cmd + click on the table. This will open the table you are querying next to your query window. You can then see the columns in the table you are dealing with. I use this every day.
Pro tip: If you place your cursor where you want the column name to go and click the column, it will embed into your query. Neato. Here’s a LinkedIn post of me demoing it.
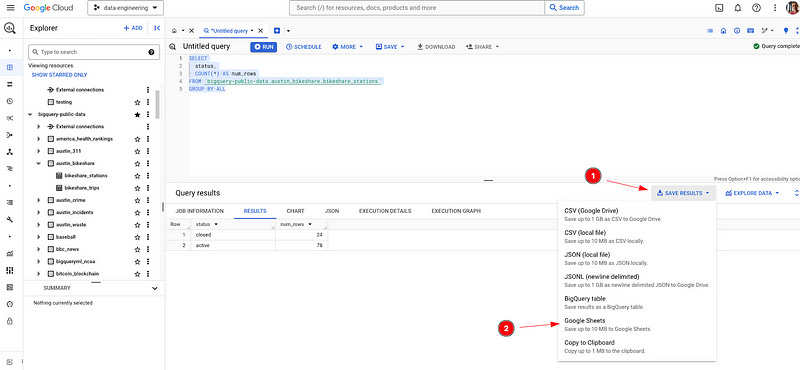
4 — Save Query Results to Google Sheets
You’ve written your little query. Now you want to pass the results to Sally in finance, who will do some magic with the numbers. Well, you can load the result directly to a Google Sheet instantly.
A lot of people moan about Excel and Google Sheets, but I regularly load things into Google Sheets to mess around and double-check numbers, etc. Also, it’s an insanely powerful tool and skill to have. Most non-tech people are wizards at it. The fashion industry practically runs on Excel.
Where to find it:
Execute your query in the Query results pane.
Click “SAVE RESULTS”.
Select Google Sheets (or anything else in that list).
Wait for the Google Sheet link to appear. Boom!
5 — Find Those Queries from Yesterday or Last Week
Job history has saved my ass countless times. Here’s the scene: you ran a query late Friday afternoon. You logged off for the weekend. Monday comes, oh damn, the browser closed, script is gone, or has it?
Nope, BigQuery has your back. Actually, Job History has it. You can use Job History to see all the queries you’ve run since the dawn of time (there must be some kind of limit, but I can’t be arsed to look it up). It’s a long time, leave it at that.
One bummer is it’s not very obvious to find.
Where to find it:
SEE BOTTOM OF SCREEN FOR BUTTON
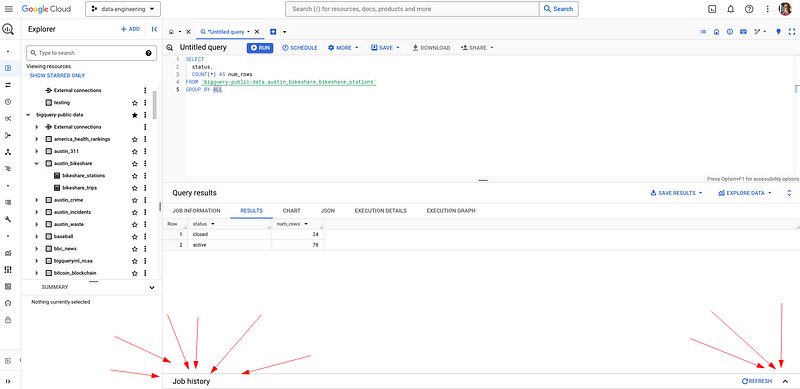
Every query you write is saved there — you have access to both your own personal job history and the project history (depending on permissions) in the project you are currently using.
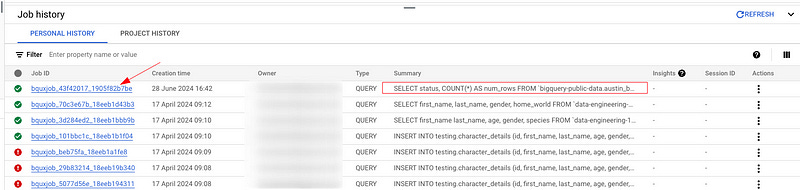
Why this is useful for me:
You can check the job details like duration, start/end times, the amount of resources, and amount queried.
You didn’t save your query that you ran yesterday? You can retrieve it from there or see what queries others have run.
You had a long-running query recently and want to see the results again without running it again? You can find the temporary table destination and query that. (Note: temporary tables only last 24 hours).
Love that you can search and filter for queries too.
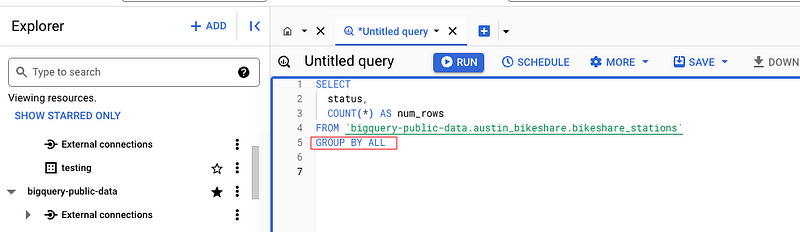
6 — GROUP BY ALL
I know this has been around for a while in Snowflake, but it hit BigQuery this year and I’m not looking back.
You got to love GROUP BY ALL.
Gone are the days of typing out column names in your GROUP BY like some kind of caveman or like some guy on crack putting GROUP BY 1,2,3.
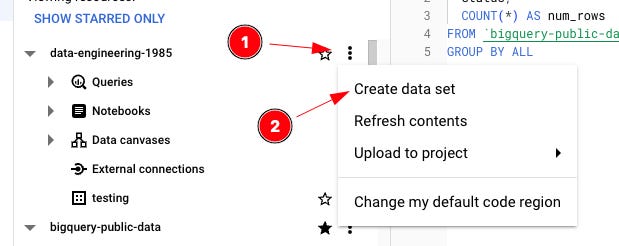
7 — Create a Temp Dataset
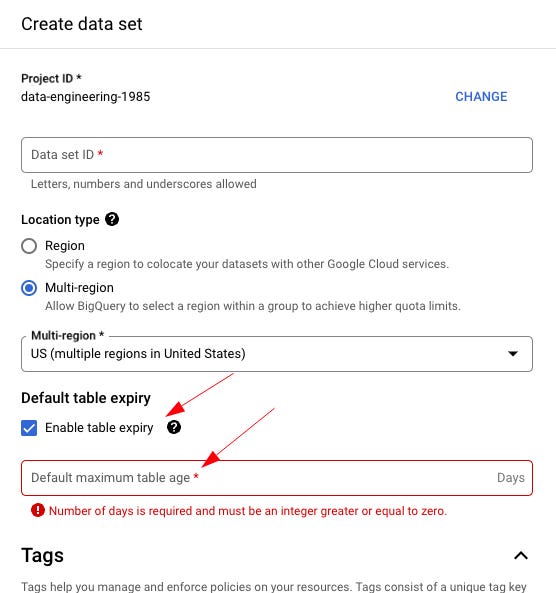
If you’re new to BigQuery, do yourself a massive favor and create a temp dataset for all your testing, development, checking, messing around, and, well, let’s face it, garbage to live.
Then, in the dataset, set the Default table expiry so that tables in your temp dataset go bye-bye after a few days.
I use a temp dataset every day for something or other. It’s useful to have and a great place for testing all sorts of things.

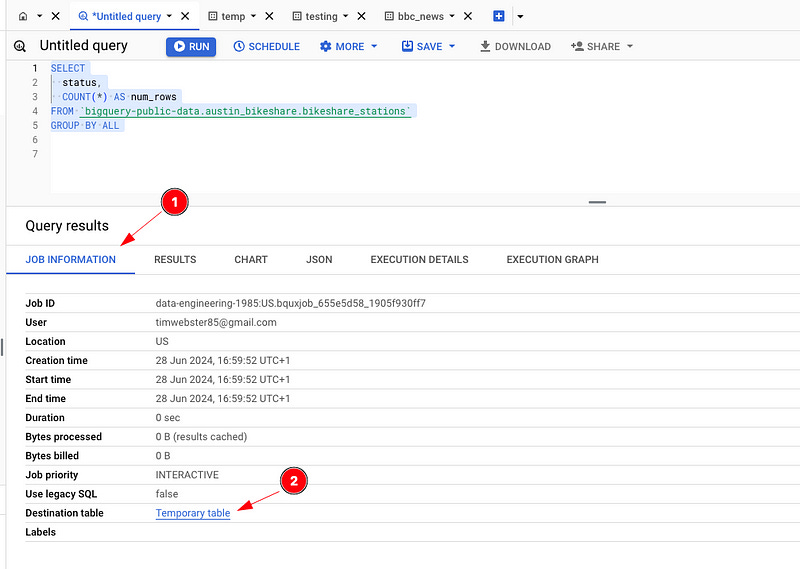
8 — Temporary Table Magic
When BigQuery runs a query, it writes that data to a temporary table (behind the scenes). Most users of BigQuery are oblivious to this fact. The great thing about this temporary table is that you can access it and query it, and that, dear reader, is magic for you!
Where to find it:
Write your SQL query and run it to get your results returned.
In the Query results pane, click the JOB INFORMATION tab.
Scroll down to the bottom of all the information, and you will find ‘Destination table,’ the temporary table hyperlink — click it.
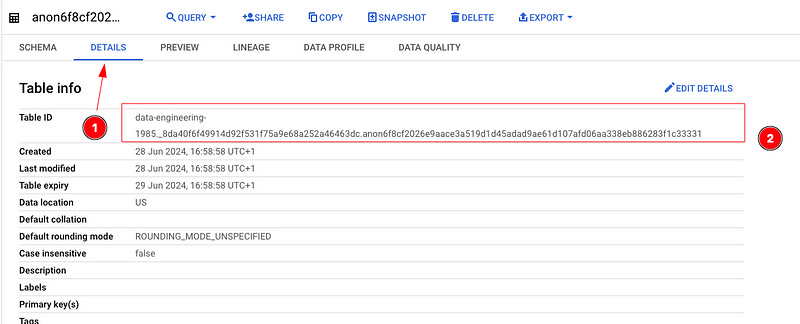
It will take you to the table details for this temporary table.
Select the DETAILS tab and grab the table ID.
Open a new query, and away you go with querying the table.
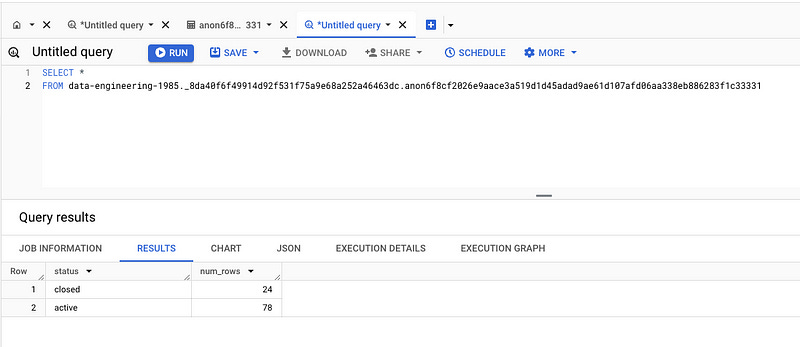
Why this is useful for me:
Quick access to review and explore the data. I look for inconsistencies, issues, problems — do the results look the way they should?
I can use this temporary table as a starting point to develop a more complex query.
Great for troubleshooting and looking at data issues step by step.
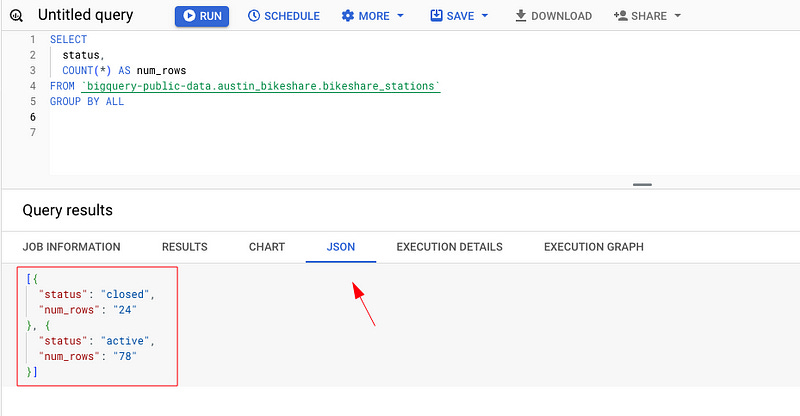
9 — Results in JSON
Want your results in JSON format? No problem, just click the JSON button. Boom!
Where to find it:
Write your SQL query and run it to get your results returned.
Then, in the Query results pane, click the JSON tab.
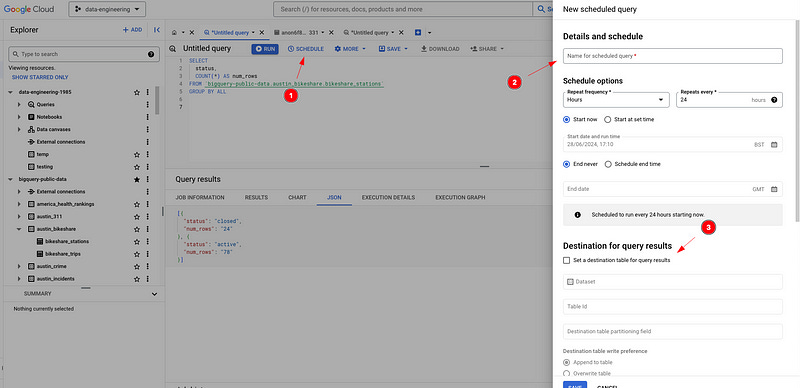
10 — Quick and Dirty Script Automation
Want to automate a SQL script real fast, load data into a table every Monday? Sure thing.
How to do it:
Write your SQL script.
Click the SCHEDULE button and boom, away you go!
Fill in the details: name, schedule, destination table, that sort of thing. That’s that.
11— Use Partitions to Filter
Only use the data you need. People like to just type SELECT * and go for it. BigQuery likes that too because it will happily get you billions of rows without even thinking twice, and before you know it, you’re in a meeting room with management explaining why your little query cost $600.
So, filter your data. Filter your data. I was going to type that out 100 times, but I won’t. When you’re working with BigQuery, if the table has a partition on it, use it. One, it’s cost-effective, and two, you will likely see a performance increase in doing so.
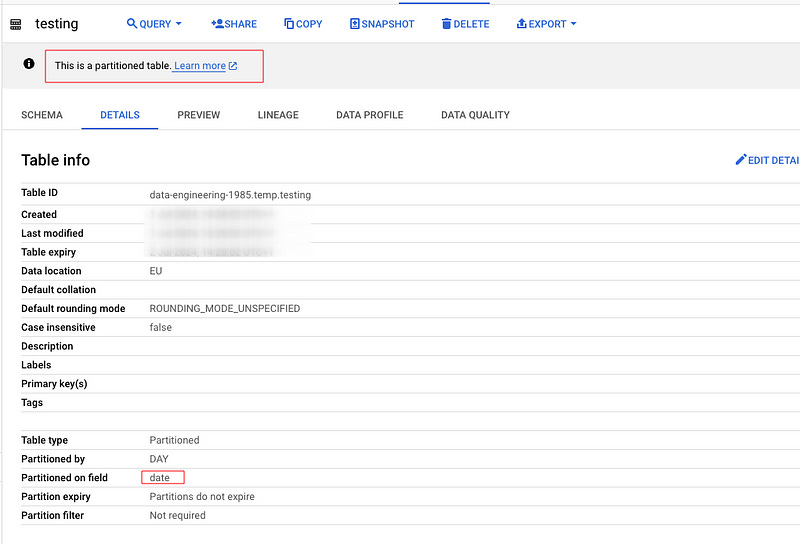
Always check if the table has a partition on it.
Where to find it:
Go to the table details.
Look at the ‘Partitioned on’ field — use that column to filter your data on.
That’s that
I aim to add more to this list over time (for me and for you), so if you’re new to BigQuery, please check back here from time to time. If you’re a BigQuery user, then please let me know some of the tips and tricks you use on a daily basis so I can add to this list. I’d love to know them.
Thanks for reading! I send this email weekly. If you would like to receive it, join your fellow data peeps and subscribe below to get my latest articles.
👉 If you enjoy reading this post, feel free to share it! Or feel free to click the ❤️ button on this post so more people can discover it on Substack 🙏
🚀 Want to get in touch? feel free to find me on LinkedIn.
🎯 Want to read more of my articles, find me on Medium.
✍🏼 Write Content for Art of Data Engineering Publication.